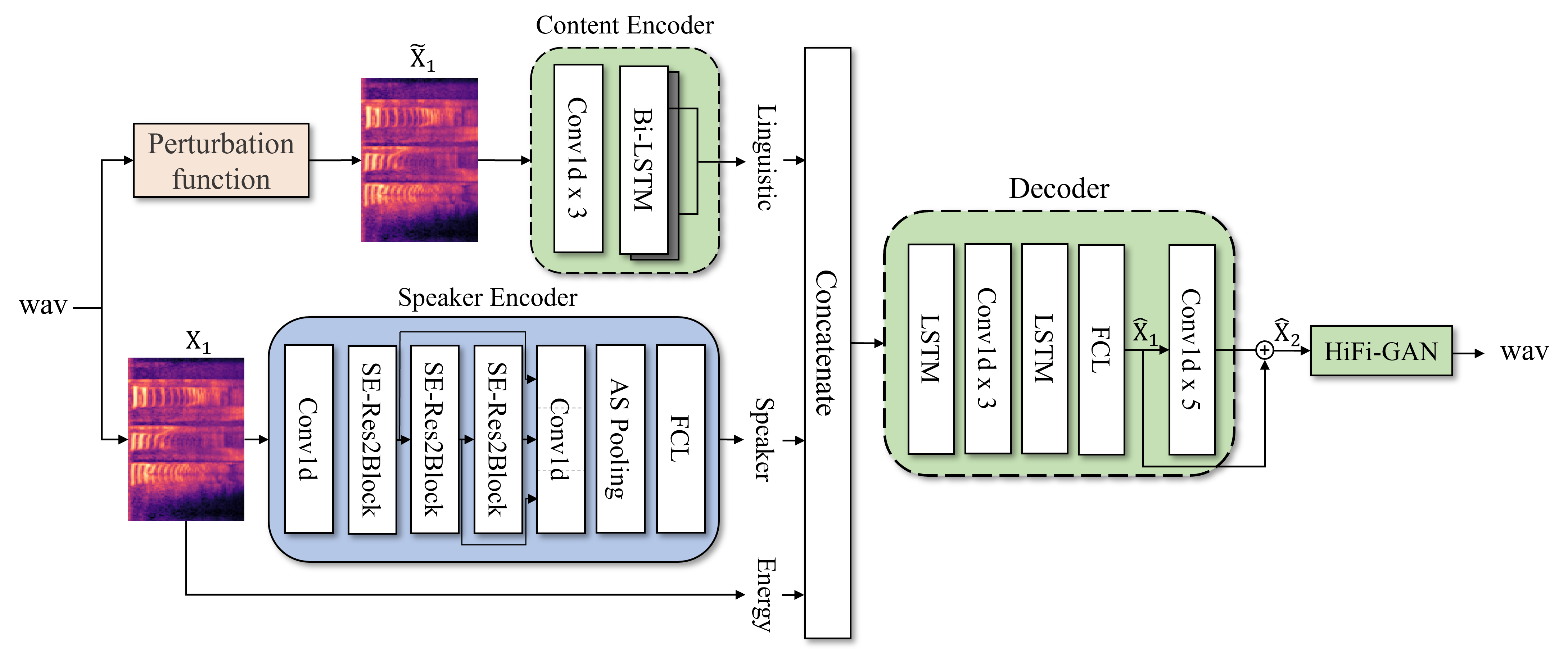
Zero-shot Voice Conversion
A technique for effectively disentangling linguistic and speaker information in non-parallel data environments using Information Perturbation-based Autoencoders. It overcomes the limitations of traditional bottleneck methods to maximize speaker similarity without compromising audio quality, and we are expanding research into high-fidelity generation models combined with Diffusion models.
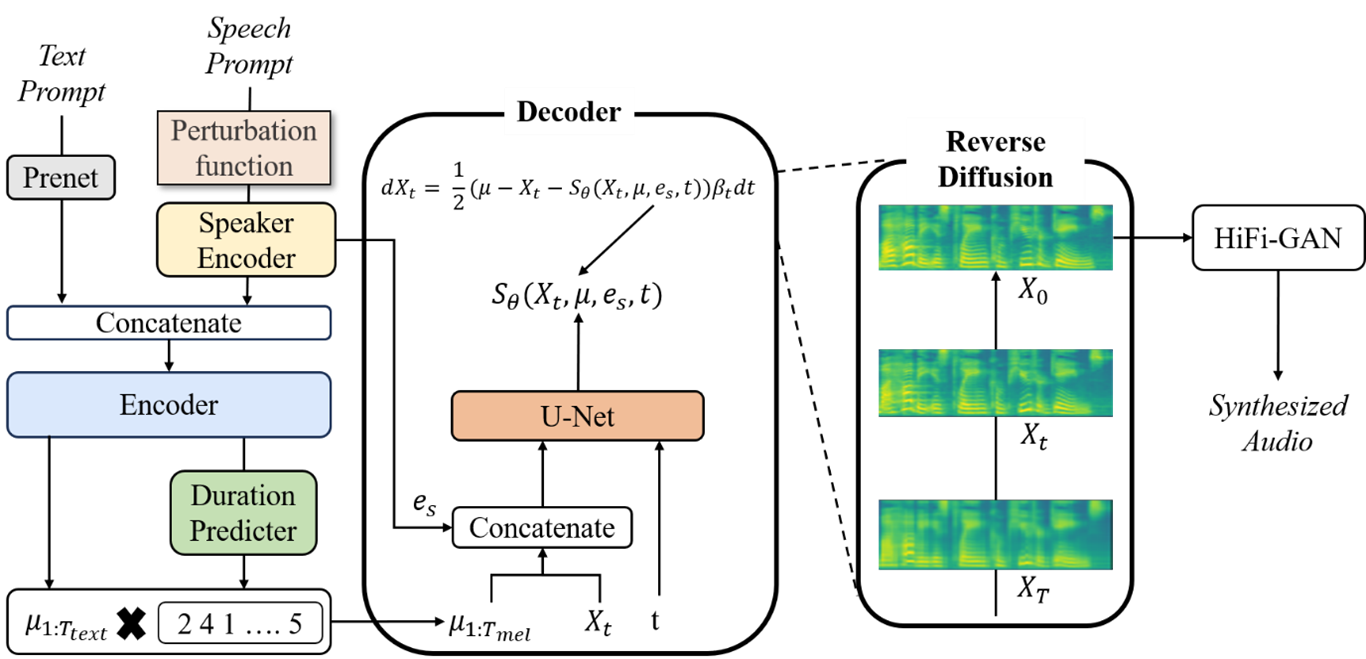
Zero-shot Speech Synthesis
A Zero-shot Multi-Speaker TTS technology based on improved Grad-TTS (Diffusion probabilistic models), capable of instant speech generation for unseen speakers. We aim to achieve both high-speed sampling and natural prosody generation by integrating Transformer-based text encoders with Score-based Decoders.
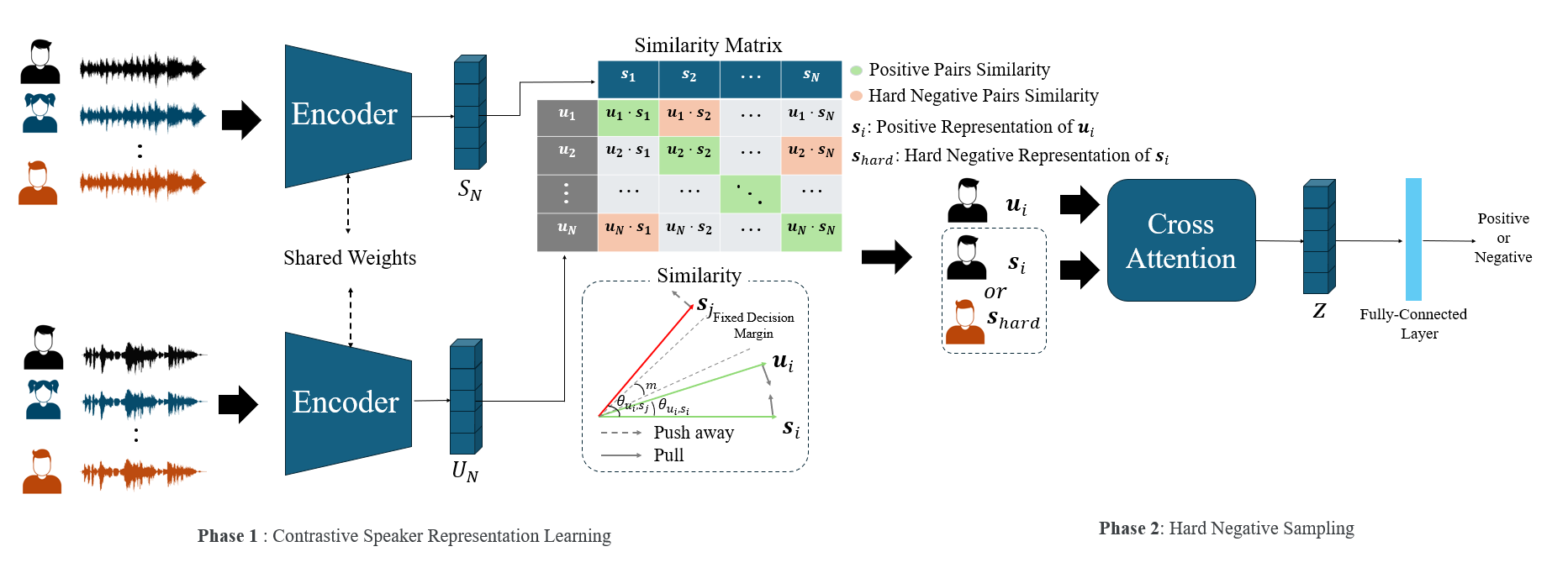
Speaker Recognition
A robust speaker recognition framework that enhances identification performance between similar speakers by combining Contrastive Learning and Hard Negative Sampling. By applying CLIP's One-to-Many relationship learning technique to the audio domain, we secure state-of-the-art representation performance in large-scale datasets like VoxCeleb.